
Data entry is a necessary evil. It’s an essential task whether you’re a finance professional, running a small business, or getting ahold of your personal finances and household budget. There are a number of finance and accounting software programs out there to help you get all of your information organized, but nothing that will do the grunt work of data entry for you. Until, that is, optical character recognition (OCR) came along. This visual analysis technology replicates natural human cognizance for a solution worthy of the Digital Age.
Not all OCR programs are created equal…
Optical recognition technology evaluates image files and translates them into usable data. As science-fiction as that may sound, OCR has quickly established itself within a real-life context. Law firms use it to search for information in 100-page depositions. Businesses can classify and index invoices with OCR barcodes. The post office uses it to sort mail by zip code. You may have even used OCR when depositing a check into an ATM.
Though this technology can be used within a variety of frameworks, the function is the same. OCR programs begin by creating a hierarchy of information. First it analyzes the layout of an image file (such as a PDF), identifying tables, columns, and text blocks. It then breaks down that information into lines and characters. Most programs then cross reference the structure of the document with the recognizable characters and an internal dictionary to provide a comprehensive overview of the content. This entire process of analysis and conversion of a page into usable data take less than a minute.
…For that matter, nor are PDFs
Many documents that you will encounter in the accounting sphere are text-based PDFs. Invoices and bank statements are often transmitted from institution to individual in this format. In these types of PDFs, you can select and copy items to paste into spreadsheets and accounting forms. But there may be times when you get an a PDF that doesn't have any clickable fields; what do you do then?
Your file is most likely image-based. Image-based PDFs are large, high-resolution photos or scanned copies of physical documents. On rare occasions, you may receive a PDF that looks and behaves like it is text-based, but when you paste a selection onto a form, it shows up like this:
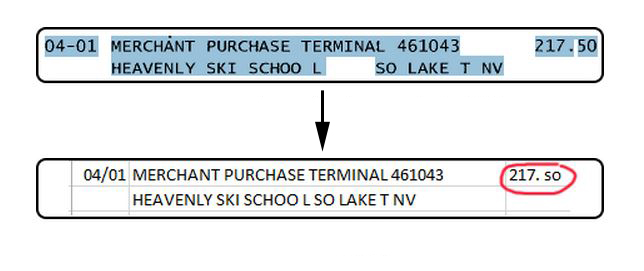
You’ve just come upon an encrypted PDF. These PDFs are meant to keep sensitive information confidential, but very few banks use them. Often, internally encrypted PDFs must be converted into image-based PDFs for processing.
Although image-based PDFs are an easy and accurate way of conveying information from one person to another, it relies upon human interpretation. Upon receiving the image, you (or your team member) have to read and manually enter that data. Not only is this time consuming, but the accuracy of data entry is subject to human faults, such as fatigue, boredom, and simple error. During periods of high volume—such as tax season—this puts your information at risk.
PinPoint OCR for the most accurate financial forms.
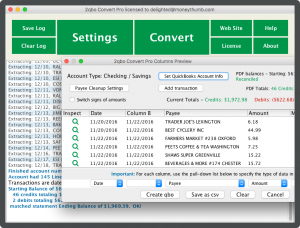
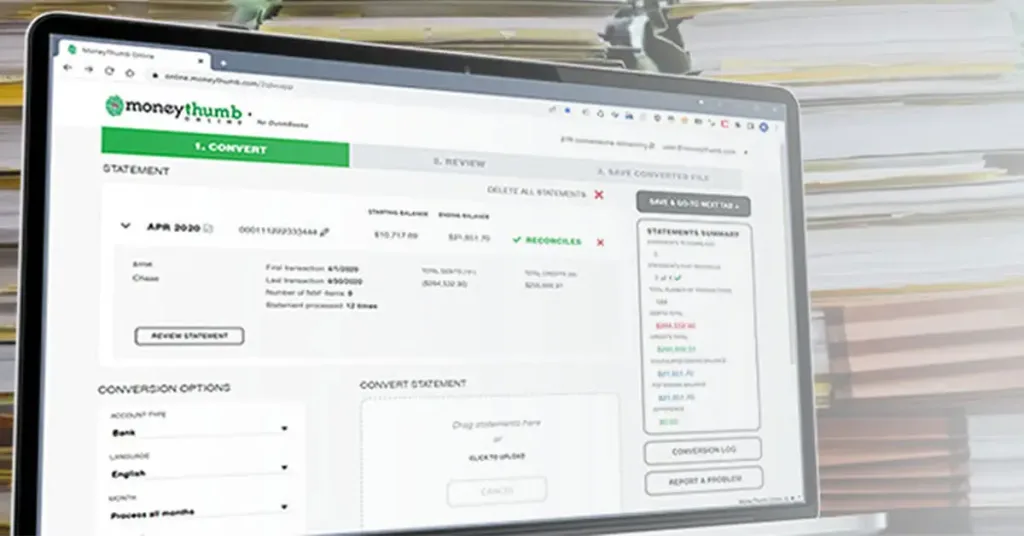
The use of an OCR program can drastically cut down on time and substantially reduce the possibility of error, but we take this a step further. MoneyThumb's new PDF+ line uses PinPoint OCR to integrate with our standard text-based converter products to give you the first character recognition program designed specifically to recognize elements within bank statements. This contextual format provides superior structural analysis and error correction.
Extracting data from financial documents such as credit card and brokerage statements for your personal finance and accounting files has never been easier. Explore our PDF+ products and see what we mean.















Add comment